Multimedia Processing
The past years have witnessed a significant increase in both the amount of multimedia content and in the data volume of the content itself. Advancing coding and delivery technologies have become indispensable to stream, deliver, and/or store this content. At the same time, high performance automatic content analysis is needed to narrow the gap between multimedia content creation on the one hand, and multimedia content management and consumption on the other hand.
Research is focused on two complementary fields: efficient representations of multimedia data, and network-based data streaming and delivery, as described below.
The research at IDLab focuses on the following complementary fields:
- Efficient representations of multimedia data. IDLab’s focus is on coding techniques for highly interactive high-quality visual applications and includes techniques for real-time and low-delay video coding, AR/VR coding and streaming, generalized coding approaches for multi-dimensional visual data, scalable compression schemes for 3D-meshes and even genomic data compression techniques that allow both streaming and random access.
- Network-based data streaming and delivery with a focus on dynamic end-to-end network-based QoE-aware systems: content placement (e.g., cache locations, pro-active vs. on-the-fly replication, cache replacement strategies, cooperative solutions), network control (e.g., congestion control, (re-)routing, scheduling, synchronization, prioritization), QoE assessment & quality adaptation (e.g., adaptive streaming, transcoding, scalable coding), and network cooperation (e.g., intra- and inter-network collaboration, CDNi, network federation).
- Text analysis and interpretation. This includes fundamental and applied research on natural language processing techniques such as spatio-temporal named entity recognition, semantic annotation, and supervised and unsupervised (deep) learning techniques to handle short and syntactically incorrect texts.
- Image and video processing. Classical techniques such as enhancement, segmentation, clustering are combined with deep learning to interpret multimodal images and video and to make the content easily accessible, and this in a broad range of application domains (media, safety and security, sports and health and industry).
- Speech and audio processing. Our portfolio covers techniques to extract verbal information (what is being said) and non-verbal information (how is something said, who is speaking) as well as techniques for detailed assessment. The focus is on robust techniques that work well in real applications.
V-FORCE
V-FORCE focuses on “Streaming 4K video as efficiently as possible – without giving in on quality of experience”
Internet traffic is currently dominated by video streaming applications. Video streaming providers are therefore straining to provide the best service to their users. The V-FORCE project aims to improve the users’ streaming experience by reducing video freezes and the live delay of live ultra-HD videos. A demostrator was built to showcase these solutions. The demo shows an objective comparison between 4K and HD resolution, in order to investigate whether the final user is able to perceive any visual difference between the two.

Graphine Software
As a Ghent University & imec spin-off, Graphine creates texture streaming and texture compression technologies for the video game and 3D visualization industries. The company was founded in 2013 by three former IDLab researchers and commercializes technology that was developed in the context of IDLab research projects (PhD and industrial).

SpotShop
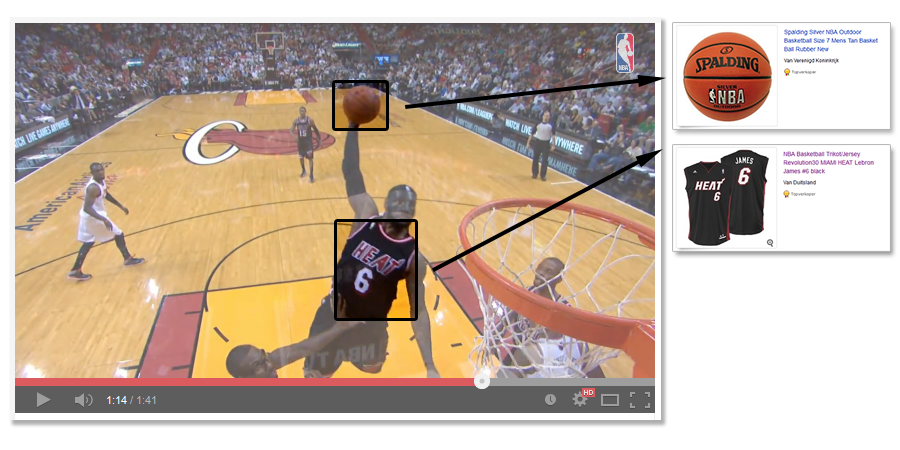
SpotShop uses fast and accurate audio-based synchronization of live, on-demand, or recorded television content with an extensive SpotShop database to offer information on products or brands seen on the screen. The SpotShop database is built with the help of automatic image recognition algorithms and links time indices with products from existing e-shops and consumer tailored promotions from the producers and advertisers.
SELVIE & crowdvid.io
crowdvid.io, a start-up initiative resulting from the SELVIE project, develops a scalable cloud backend as well as an Android and iPhone application that help live event organizers (such as festivals, sports manifestations or gigs) looking for new ways to engage their audience during their live events, to automatically collect short videos from within their audience, direct them through a intuitive web interface and seamlessly integrate them into their existing video production environments, all this taking into account the upload bandwidth available during the upload phase.